js基础心法之数据分类
时间:2024/5/28作者:未知来源:争怎路由网人气:5
- 网页的本质就是超级文本标记语言,通过结合使用其他的Web技术(如:脚本语言、公共网关接口、组件等),可以创造出功能强大的网页。因而,超级文本标记语言是万维网(Web)编程的基础,也就是说万维网是建立在超文本基础之上的。超级文本标记语言之所以称为超文本标记语言,是因为文本中包含了所谓“超级链接”点。一个很基础的知识点,这篇主要是介绍JavaScript中基本数据类型和引用数据类型是如何存储的,需要的朋友可以参考下
由于自己是野生程序员,在刚开始学习程序设计的时候没有在意内存这些基础知识,导致后来在提到“什么什么是存在栈中的,栈中只是存了一个引用”这样的话时总是一脸懵逼。。
后来渐渐的了解了一些内存的知识,这部分还是非常有必要了解的。
基本数据结构
栈
栈,只允许在一段进行插入或者删除操作的线性表,是一种先进后出的数据结构。
堆
堆是基于散列算法的数据结构。
队列
队列是一种先进先出(FIFO)的数据结构。
JavaScript中数据类型的存储
JavaScript中将数据类型分为基本数据类型和引用数据类型,它们其中有一个区别就是存储的位置不同。
基本数据类型
我们都知道JavaScript中的基本数据类型有:
String
Number
Boolean
Undefined
Null
Symbol(暂时不管)
基本数据类型都是一些简单的数据段,它们是存储在栈内存中。
引用数据类型
JavaScript中的引用数据类型有:
Array
Object
引用数据类型是保存在堆内存中的,然后再栈内存中保存一个对堆内存中实际对象的引用。所以,JavaScript中对引用数据类型的操作都是操作对象的引用而不是实际的对象。
可以理解为,栈内存中保存了一个地址,这个地址和堆内存中的实际值是相关的。
图解
现在,我们声明几个变量试试:
var name="axuebin"; var age=25; var job; var arr=[1,2,3]; var obj={age:25};可以通过下图来表示数据类型在内存中的存储情况:
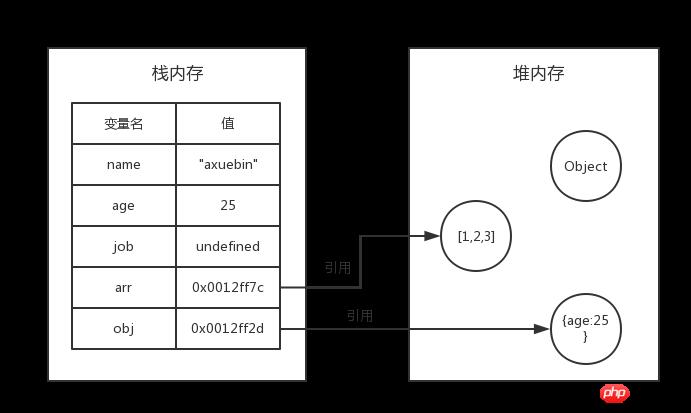
此时
name,age,job三种基本数据类型是直接存在栈内存中的,而arr,obj在栈内存中只是存了一个地址来表示对堆内存中的引用。复制
基本数据类型
对于基本数据类型,如果进行复制,系统会自动为新的变量在栈内存中分配一个新值,很容易理解。
引用数据类型
如果对于数组、对象这样的引用数据类型而言,复制的时候就会有所区别了:
系统也会自动为新的变量在栈内存中分配一个值,但这个值仅仅是一个地址。也就是说,复制出来的变量和原有的变量具有相同的地址值,指向堆内存中的同一个对象。
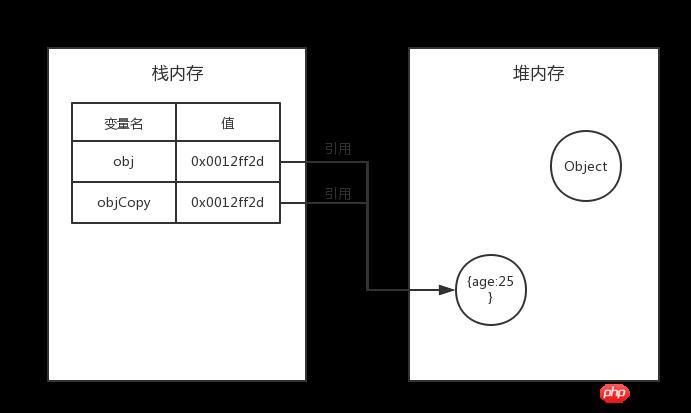
如果所示,执行了var objCopy=obj之后,obj和objCopy具有相同的地址值,执行堆内存中的同一个实际对象。
这有什么不同呢?
当我修改obj或objCopy时,都会引起另一个变量的改变。
为什么?
为什么基础数据类型存在栈中,而引用数据类型存在堆中呢?
堆比栈大,栈比对速度快。
基础数据类型比较稳定,而且相对来说占用的内存小。
引用数据类型大小是动态的,而且是无限的。
堆内存是无序存储,可以根据引用直接获取。
参考文章
理解js内存分配
原始值和引用值
在ECMAScript中,变量可以存放两种类型的值,即原始值和引用值。
原始值指的就是代表原始数据类型(基本数据类型)的值,即Undefined,Null,Number,String,Boolean类型所表示的值。
引用值指的就是复合数据类型的值,即Object,Function,Array,以及自定义对象,等等栈和堆
与原始值与引用值对应存在两种结构的内存即栈和堆
栈是一种后进先出的数据结构,在javascript中可以通过Array来模拟栈的行为原始值是存储在栈中的简单数据,也就是说,他们的值直接存储在变量访问的位置。
堆是基于散列算法的数据结构,在javascript中,引用值是存放在堆中的。
引用值是存储在堆中的对象,也就是说,存储在变量处的值(即指向对象的变量,存储在栈中)是一个指针,指向存储在堆中的实际对象.例:var obj = new Object(); obj存储在栈中它指向于new Object()这个对象,而new Object()是存放在堆中的。
那为什么引用值要放在堆中,而原始值要放在栈中,不都是在内存中吗,为什么不放在一起呢?那接下来,让我们来探索问题的答案!
首先,我们来看一下代码:function Person(id,name,age){ this.id = id; this.name = name; this.age = age; } var num = 10; var bol = true; var str = "abc"; var obj = new Object(); var arr = ['a','b','c']; var person = new Person(100,"笨蛋的座右铭",25);然后我们来看一下内存分析图:
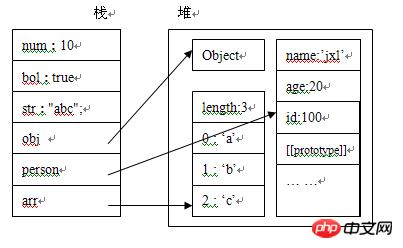
变量num,bol,str为基本数据类型,它们的值,直接存放在栈中,obj,person,arr为复合数据类型,他们的引用变量存储在栈中,指向于存储在堆中的实际对象。
由上图可知,我们无法直接操纵堆中的数据,也就是说我们无法直接操纵对象,但我们可以通过栈中对对象的引用来操作对象,就像我们通过遥控机操作电视机一样,区别在于这个电视机本身并没有控制按钮。
现在让我们来回答为什么引用值要放在堆中,而原始值要放在栈中的问题:
记住一句话:能量是守衡的,无非是时间换空间,空间换时间的问题
堆比栈大,栈比堆的运算速度快,对象是一个复杂的结构,并且可以自由扩展,如:数组可以无限扩充,对象可以自由添加属性。将他们放在堆中是为了不影响栈的效率。而是通过引用的方式查找到堆中的实际对象再进行操作。相对于简单数据类型而言,简单数据类型就比较稳定,并且它只占据很小的内存。不将简单数据类型放在堆是因为通过引用到堆中查找实际对象是要花费时间的,而这个综合成本远大于直接从栈中取得实际值的成本。所以简单数据类型的值直接存放在栈中。
总结:以上就是本篇文的全部内容,希望能对大家的学习有所帮助。更多相关教程请访问JavaScript视频教程!
相关推荐:
以上就是js基础心法之数据类型的详细内容,更多请关注php中文网其它相关文章!
网站建设是一个广义的术语,涵盖了许多不同的技能和学科中所使用的生产和维护的网站。
关键词:js基础心法之数据分类