百度等大型网站收录页面提交入口分享
时间:2024/4/4作者:未知来源:争怎路由网人气:5
- 图形(Graph)和图像(Image)都是多媒体系统中的可视元素,虽然它们很难区分,但确实不是一回事。图形是矢量图(Vector Drawn),它是根据几何特性来绘制的。图形的元素是一些点、直线、弧线等。图像是位图(Bitmap),它所包含的信息是用像素来度量的。
大型网站会收入各种各样的网页,当然需要大家自己去提交网页。有不少的朋友表示不知道这个到哪里提交。小编整理了一下,下面就将这些提交入口和大家分享一下。
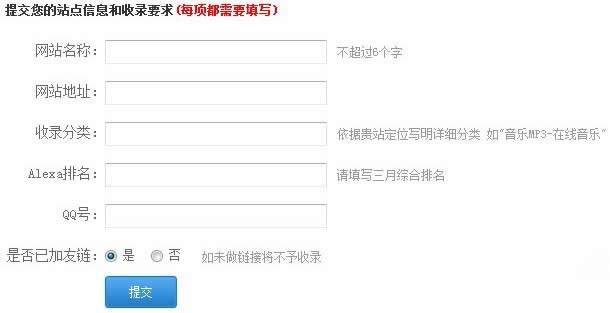
提交站点信息360搜索引擎登录入口: http://info.so.360.cn/site_submit.html?from_cr173.com。
百度单个网页提交入口: http://zhanzhang.baidu.com/sitesubmit?from_cr173.com。
搜狗网站收录提交入口: http://www.sogou.com/feedback/urlfeedback.php?from_cr173.com。
搜索引擎
搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。百度和谷歌等是搜索引擎的代表。
工作原理
第一步:爬行
搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链接,像蜘蛛在蜘蛛网上爬行一样,所以被称为“蜘蛛”也被称为“机器人”。搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容。
第二步:抓取存储
搜索引擎是通过蜘蛛跟踪链接爬行到网页,并将爬行的数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的。搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步:预处理
搜索引擎将蜘蛛抓取回来的页面,进行各种步骤的预处理。
⒈提取文字。
⒉中文分词。
⒊去停止词。
⒋消除噪音。(搜索引擎需要识别并消除这些噪声,比如版权声明文字、导航条、广告等……)
5.正向索引。
6.倒排索引。
7.链接关系计算。
8.特殊文件处理。
除了HTML 文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。 但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
第四步:排名
用户在搜索框输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程与用户直接互动的。但是,由于搜索引擎的数据量庞大,虽然能达到每日都有小的更新,但是一般情况搜索引擎的排名规则都是根据日、周、月阶段性不同幅度的更新。
相信有不少朋友对搜索引擎这方面的内容知之甚少,因此除了为大家介绍网页提交入口外,小编还附带介绍了一下搜索引擎,及其工作原理,希望能帮到大家。
矢量图常用于框架结构的图形处理,应用非常广泛。图形是人们根据客观事物制作生成的,它不是客观存在的;图像是可以直接通过照相、扫描、摄像得到,也可以通过绘制得到。
关键词:百度等大型网站收录页面提交入口分享